Partial Annotation in Object Detection
In this post, I discuss two papers that tackle the challenge of partially annotated datasets. But first, why should we care about missing annotations in detection? For starters, labeling bounding boxes is tedious and error-prone. Expanding the taxonomy only amplifies this burden exponentially. Consider this scenario: you have a training dataset with 20 categories, and later want to incorporate 10 new ones. Must you re-annotate the entire dataset? Or can some clever technique handle this automatically? With the emergence of the Open Images Dataset—containing a staggering number of images and annotations—the community has grown increasingly interested in this problem. Here are two papers I found particularly illuminating:
- Wu, Zhe, et al. “Soft sampling for robust object detection.” arXiv preprint arXiv:1806.06986 (2018).
- Niitani, Yusuke, et al. “Sampling Techniques for Large-Scale Object Detection from Sparsely Annotated Objects.” arXiv preprint arXiv:1811.10862 (2018).
In the first paper, the authors investigate how robust object detection systems are when annotations go missing. I have explored this phenomenon myself with COCO-like datasets, though the authors take a far more systematic approach to their experiments. Their conclusion is intriguing:
we observe that after dropping 30% of the annotations (and labeling them as background), the performance of CNN-based object detectors like Faster-RCNN only drops by 5% on the PASCAL VOC dataset.
Here is the catch: this conclusion holds when the detection threshold is set to 0—hardly practical for real-world applications. Any production system must use higher thresholds to achieve acceptable precision/recall trade-offs. Indeed, at thresholds above 0.4, we observe a significant mAP drop, which makes perfect sense. To their credit, the authors acknowledge in Section 4 that “it is important for practitioners to tune the detection threshold per class when using detectors trained on missing labels.”
A telling illustration appears in Figure 2, which charts performance changes
on the trainval and test sets of VOC2007 across various detection thresholds.
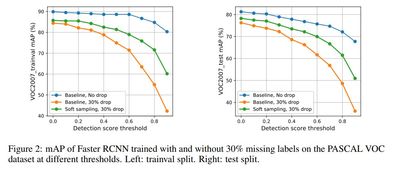
One important experimental detail: they drop ground-truth boxes uniformly across all classes—quite different from the scenario of adding new categories to an existing model. The former preserves the taxonomy; the latter fundamentally reshapes the entire label structure.
Now for the proposed method. First, they advocate hard example mining to address missing annotations—the rationale being that hard example mining naturally steers away from randomly sampling unannotated regions. They then introduce a gradient weighting function based on IoU overlap. At this point, astute readers will recognize this as essentially another incarnation of the Balanced IoU Sampler.
So, there is nothing surprising here.
The authors also propose a second approach (otherwise, the paper would be rather slim for conference publication). This time, they weight gradients for ROIs that are neither positives nor hard negatives. The weighting function resembles the previous one. Essentially, they place faith in the model’s predictions: if an ambiguous ROI (neither positive nor hard negative) receives a high confidence score, treat it as positive and amplify its gradient; otherwise, dampen it. The authors candidly admit that the trained model remains weak, so this bootstrapping approach falls short. The experimental results confirm this observation.
On to the second paper. Their method, dubbed pseudo label-guided, rests on a simple observation: when an object appears in an image, its constituent parts likely appear as well. Spot a car? Expect to find tires nearby. This reasoning, of course, only applies to hierarchical taxonomies where part-whole relationships exist.
The proposed method is composed of two components:
-
part-aware sampling: they simply ignore the classification loss of part categories when an instance of them is inside an instance of their subject categories.
-
pseudo labels: to exclude regions that are likely not to be annotated.
In essence, they strategically ignore regions suspected of harboring missing annotations.
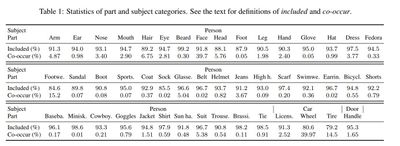
Table 1. in the paper is interesting. There are two notions here:
- Included: the ratio of part components co-located with their subject category in the same instance to the total bounding boxes of the part component.
- Co-occur: the ratio of images containing both part and subject categories to the total images having subject categories.
These numbers paint a sobering picture: missing annotations pervade the Open Images Dataset.
The paper summarizes both algorithms formally, but a plain-English translation proves helpful:
-
Part-aware sampling: For each RoI proposal (Line 1), check whether the associated ground-truth (Line 3) contains part categories (Line 4). If so, ignore labels (Line 6) that have not been verified (Line 5).
-
Pseudo label-guided sampling: For each output from a trained model (Line 2), discard entries whose score falls below the threshold or whose label belongs to the verified set (Line 3); also discard any that lie too close to existing ground-truth (Line 6). Then, for each RoI proposal (Line 8), add boxes from the filtered output to the ignored set (Line 11) if their IoU with the RoI exceeds the threshold (Line 10).
Experiments
Nothing groundbreaking here—standard experimental validation. That said, I plan to implement soft sampling and pseudo label-guided sampling in the coming weeks. Time will tell whether these methods genuinely improve my own work.