Adaptive Threshold
Survey
Adaptive threshold (or Ranked List Truncation) has been evolving since the 2000s. Prior to the Deep Learning era, researchers modeled the score distribution (Arampatzis et al. 2009):
- The similarity score follows a mixture of distributions.
- Typically, it comprises two components: (1) relevant scores, and (2) irrelevant scores.
- Relevant scores: commonly modeled as a Gaussian distribution.
- Irrelevant scores: modeled as a (truncated) exponential distribution.
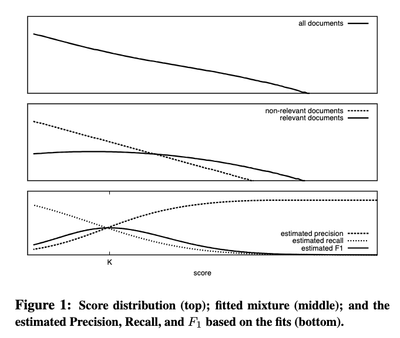
To learn the parameters of those distributions, an EM algorithm is applied with labelled training data. A recent attempt uses extreme value theory to model the score (paper) (Bahri et al. 2023).
Enter the DL era, where we can train a discriminative network to determine whether a score belongs to relevant or irrelevant products. BiCut (Bahri et al. 2020) frames the problem as deciding whether the current product serves as a good stopping point, training a network to predict “continue” or “stop.” Choppy (Meng and others 2024), on the other hand, revisits the traditional approach: modeling the score distribution given the ranked list using a deep network.
Despite these novel approaches to truncated reranking, a recent benchmark (Meng and others 2024) offers some noteworthy insights:
- DL-based approaches aren’t significantly better than unsupervised or simpler methods (top-K cutoff).
- Incorporating query embeddings into the network shows no clear advantage.
- Distribution-based approaches generally outperform sequence-based ones.
- With effective retrievers (at the recall stage), even a straightforward top-K approach yields a favorable trade-off between effectiveness and efficiency.
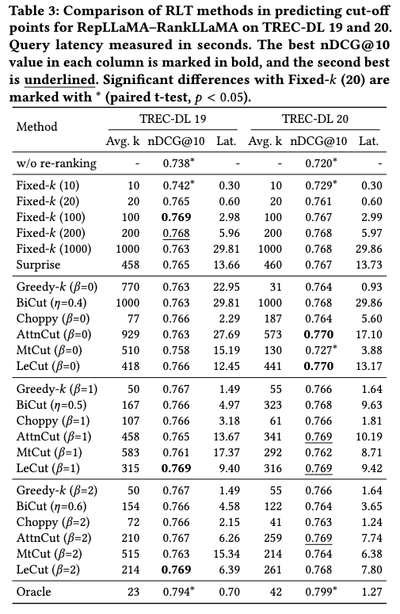
Note that the authors use NDCG@10 to evaluate.
Key takeaways from these findings:
- Quality embeddings remain essential, with or without adaptive thresholding.
- The greedy approach already performs well. More sophisticated (DL-based) methods may not justify their complexity given the marginal improvements and latency overhead.
Design
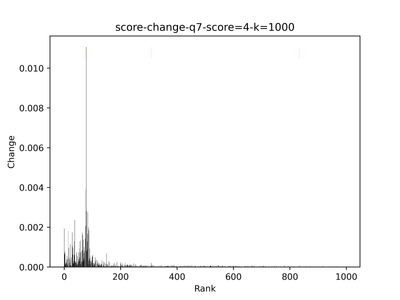
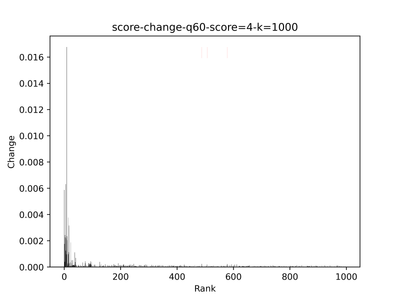
My idea is much simpler: whenever the score drops dramatically (indicating one of the embeddings has a negligible score), we stop returning results. The problem then becomes finding the peak(van Brakel 2014)[1] in the stream of score changes.
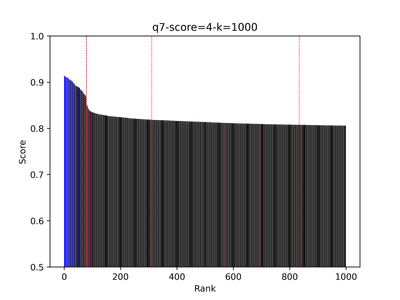
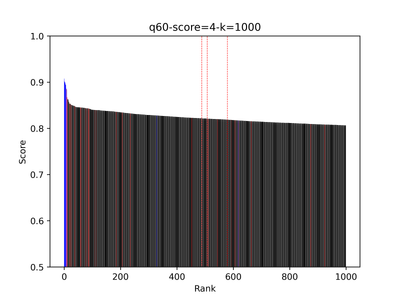
Below is an example showing the score values of the top 1,000 results—blue indicates positive, red indicates negative, and black marks unannotated items. The leftmost dashed red line shows the cutoff point.
| Score Visualization | Score Gradient |
|---|---|
 |
 |
 |
 |
For product search, recall matters significantly, so we want to avoid premature cutoffs. In my implementation, I always return the top 50 results, assuming this set will include all exact matches and relevant products. Beyond the 50th result, results tend to mix relevant and partially relevant items—a zone that can be safely trimmed. Additionally, adaptive thresholding helps prevent the reranker from pushing irrelevant products to the top of the list. The second example illustrates a case where this approach falls short: the cutoff occurs too late, and the final results contain too many irrelevant items. This likely represents an exact-match search, where users copy a product title into the search bar.
Why not adopt the mixture model approach? It requires training data; although ChatGPT could certainly annotate them, doing so would complicate the release timeline. Meanwhile, DL-based approaches seem excessive and haven’t demonstrated significant improvements.
Caveats
This certainly isn’t an optimal solution. After releasing this feature, we observed several issues:
- The current implementation prioritizes precision by cutting off the rank list as early as possible, which dramatically reduces recall—a significant drawback for product search.
- The score distribution for each query depends heavily on the query type: exact, feature-based, or symptom-based searches. Each type may exhibit a different distribution. For instance, continuing to return partially relevant results for exact searches might enhance recall and potentially improve conversion rates.
I also spotted a bug. See also (van Brakel 2014). ↩︎
References
- Arampatzis, Avi, Jaap Kamps, and Stephen Robertson. 2009. “Where to Stop Reading a Ranked List? Threshold Optimization Using Truncated Score Distributions.” In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval.
- Bahri, Dara, Angelos Katharopoulos, Jean Thollot, and François Fleuret. 2020. “Choppy: Cut Transformer for Ranked List Truncation.” In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval.
- Bahri, Dara, Donald Metzler, and others. 2023. “Surprise: Result List Truncation via Extreme Value Theory.” In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval.
- Brakel, J.P.G. van. 2014. “Robust Peak Detection Algorithm Using Z-Scores.” Stack Overflow.
- Meng, Chuan and others. 2024. “Ranked List Truncation for Large Language Model-Based Re-Ranking.” In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval.