AI Challenge - Landmark: Kỹ thuật và ý tưởng
Trong bài viết này mình sẽ chia sẻ một số kỹ thuật cũng như ý tưởng có thể trong cuộc thi Zalo AI Challenge - Landmark data do team mình - VietAI - thực hiện.
Dữ Liệu
Dưới đây là phân phối số lượng ảnh trên mỗi label.
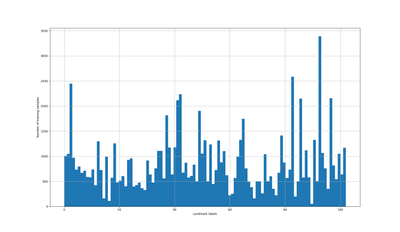
Một số class có số sample tương đối thấp, ta có thể cần 1 số technique để khắc phục vấn đề này.

Kỹ thuật
Team mình đã sử dụng 9 models khác nhau để train và sau đó stack/blend lại. Bao gồm:
- DenseNet121, DenseNet161
- Resnet50, Resnet152
- ResNext50, ResNext101
- Wide-resnet.
- Inception_v4, Inceptionresnet_v2.
[Mình đã finetune 34 models khác nhau với kiến trúc và optimizer scheme khác nhau (learning rate/ weight decay/ data augmentation không tính)]
Để tăng độ chính xác model, tụi mình có sử dụng và thử 1 số phương pháp sau [phần bôi đen là những kỹ thuật rất quan trọng để tăng hiệu quả của model]:
- Freeze network rồi finetune, sau đó unfreeze toàn bộ và train. [Thực sự hiệu quả]. Tuy nhiên lưu ý một điều: sau khi unfreeze toàn bộ các layer thì quá trình train sẽ rất chậm, ta cần phải điều chỉnh số lượng epoch ở bước này cho hợp lý.
- Sử dụng Cyclic Learning Rates (Smith 2017) [Thực sự hiệu quả]. Tham số mà mình thấy ổn nhất, cũng như có thời gian train tương đối chấp nhận được (tầm 20h/ 1 model):
cycle_length = 2, cycle_multiplier = 2, num_cycles = 4 - Adam Optimizer + Weight Decay [Improve 1 cách tương đối]. Adam giúp loss giảm nhanh hơn SGD.
- Differential Weight Decay tuy vậy không thấy cải thiện được gì.
- Stochastic Gradient Descent with Warm Restarts: khá tốt.
- Stochastic Weight Averaging: Không hiệu quả + khiến thời gian train tăng.
- Differential Learning Rate: improve tương đối.
- Data Augmentation/ Test Time Augmentation: Thực sự hiệu quả. Đây là cách hiệu quả nhất để tránh overfitting.
- Tăng kích thước ảnh: Thực sự hiệu quả. Tuy nhiên phụ thuộc vào Memory của GPUs và kiến trúc mạng. Bộ ba thần thánh của mình là:
224, 256, 299. - Sử dụng fully connected layers kết hợp với kNN làm thành 1 classifier: đây là ý tưởng của team 4th place Google Landmark Recognition - thực sự không hiệu quả trong case này [, hoặc là mình implement bậy rồi] .
- Để handle imbalance data: ta có thể dùng upsampling, downsampling hoặc sử dụng distribution khác cho sampler (mình đã implement multinomial distribution thay cho uniform của pytorch) cũng như sử dụng weighted loss (thêm weight dựa trên số lượng sample/class). Một số kỹ thuật có thể tham khảo ở đây [Link]. Khá tiếc khi phần này đã bị leader reject, trong khi top 1 Landmark đã dùng kỹ thuật này để đạt kết quả tốt ở private test.
- Để có thể chọn learning rate hợp lí và nhanh, kỹ thuật trong bài [Cyclical Learning Rates for Training Neural Networks] được sử dụng phổ biến, ta có thể plot nhiều setting của một model trên cùng 1 figure để chọn learning phù hợp. Nếu bạn lười, cứ set learning rate là
3e-4. Thánh Karpathy đã verify điều đó (Twitter).
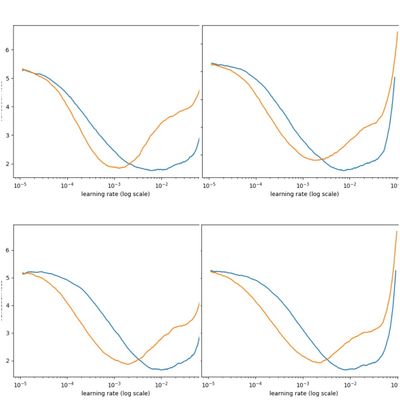
Một số bài viết hỗ trợ trong quá trình finetune:
- Playing around with SGDR [Link]
- Differential Learning Rates [Link]
- Optimization techniques comparison in Julia: SGD, Momentum, Adagrad, Adadelta, Adam [Link]
Về phần stack/blend, mình nhường lại cho leader Khả Ái (Phát); hầu như các solution trên Forum Machine Learning Cơ Bản mà các bạn top 3 post đều nằm trong plan thực hiện của Khả Ái. Nên mình tin nếu lúc đó mình làm đúng plan thì kết quả bên Landmark lẫn Music đã rất khác rồi.
[Nhân đây: Noi theo tấm gương sáng ngời cùng đường lối sáng suốt của leader , mình phát động phong trào đẩy mạnh học tập và làm theo tư tưởng, đạo đức Hoàng Quý Phát]
Other
- Mình dùng 1 Titan X, 2 1080 Ti, 1 P100 để train. Trước deadline vài ngày có dùng 1 máy Google Cloud.
- Rất nhiều hình gif bị save thành jpg, ta có thể dùng trick để avoid lỗi những ảnh này.
- Đừng sa lầy bởi code đểu, đừng nghe dân mạng chém gió và cố gắng bám sát vào plan của mình. Chỉ nên tin những nguồn đáng tin cậy.
- Sử dụng notion.so để quản lý ghi chú, kết quả thí nghiệm và lên kế hoạch.
Các ý tưởng khác
Image Retrieval - KNN
Để sử dụng kỹ thuật image retrieval hiệu quả (Radenović et al. 2019) [tức là image retrieval thực sự outperform classification] thì dataset cần hội đủ các yếu tố:
- Dataset có số lượng label rất lớn.
- Phân phối training samples không đều và chênh lệch lớn.
- Mối tương quan giữa các ảnh trong cùng 1 class thấp.
Ví dụ điển hình là tập Google Landmark với 1.5 triệu ảnh, và 15K label (landmark) khác nhau. Hình dưới cho thấy rất nhiều label có số lượng training ít.
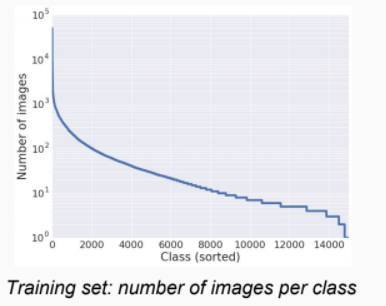
Trong 3 điều kiện trên thì tập Landmark của Zalo thỏa được (2) và (3) phần nào đó. Ví dụ ở class 0 và 1, độ tương quan khá thấp, và nếu không biết trước được rằng các hình nằm chung 1 class thì mình nghĩ đến cả human còn nhầm đây là các địa điểm khác nhau:


Ở các kỹ thuật trong retrieval có thể đơn giản hóa như sau:
- Tận dụng local features làm representation và search dựa trên Euclidean distance.
- Dùng k-NN kết hợp với kd tree (exact search) hoặc PQ (approximate search) để giảm thời gian search (lưu ý ràng buộc 6 tiếng inference) [dĩ nhiên với dataset nhỏ thì cứ dùng k-NN].
- Dùng các kỹ thuật Pooling hoặc Masking (Noh et al. 2017) thay vì dùng trực tiếp feature tầng cuối của network. Và như vậy, ta sẽ pooling ở tầng conv thay vì tầng fully connected.
Local features như RootSIFT+BoW hoặc RootSIFT+Triemb hoạt động rất tốt trong case này:

Với kỹ thuật này, ta có thể apply 1 số technique hay ho như:
- Query Expansion (Chum et al. 2007).
- Regional Diffusion (Iscen et al. 2017).
Image Retrieval cùng với các kỹ thuật này đã đạt kết quả rất tốt ở hai cuộc thi là Landmark Retrieval và Landmark Recognition của Google [Link]. Mình nghĩ ít nhiều nó sẽ giúp improve performance, đặc biệt là với class có intra-class correlation thấp.
Fine-grained Classification
Nếu ta xem xét các labels và thứ tự của nó, ta nhận ra rằng các lớp chung 1 category sẽ nằm cạnh nhau. Ví dụ:
- Từ label 17 → 23: các thể loại cầu; bao gồm: Cầu Chương Dương, Cầu Tràng Tiền, Cầu Rồng, Cầu Tình Yêu, Cầu Tay Vàng Bà Nà.
- Label từ 25 → 28: các thể loại cột cờ: Cột cờ Hà Nội, Cột cờ Hà Giang, Cột cờ Đảo Trường Sa và Cột cờ Cà Mau.
- Label 9 → 11: các chợ: Chợ Bến Thành, chợ Nổi và chợ Đồng Xuân.
- Label 71 → 79: các nhà thờ Công Giáo: Nhà Thờ Đức Bà, Nhà Thờ Nha Trang, Nhà Thờ ở Phú Yên, …
Một ý tưởng đơn giản đó là ta gom hết các data trong các nhóm đó lại với nhau thành 1 label lớn: ví dụ “chợ”, “cầu”, “cột cờ” và xây dựng bộ classifier trên đó (tạm gọi là Classifier-A). Kết quả có thể đem làm trọng số cho classifier chính với 103 classes. Ngoài ra, ta có thể “random” trong trường hợp kết quả ra thấp: Nếu bộ classifier 103 lớp không classify được, nhưng bộ Classifier-A ra kết quả là “cầu” với confidence cao, ta có thể random trong đó [Dĩ nhiên, có những phương pháp fancy hơn để inference ra kết quả]; ngay cả với random, giả sử groundtruth là 1 trong 7 loại cầu: thì ta có xác suất 1 – 6C3/7C3 = 42.8571 %. Theo bản thân mình, đây cũng là cách mà con người nhận biết landmark. Fancy hơn, bạn có thể dùng Maximum Spanning Tree Clustering [Link]
Đồng thời, với quan sát như trên, ta có thể sử dụng 1 số phương pháp fine-grained classification để cải thiện độ chính xác. Bởi theo như quan sát, các kiến trúc cầu, nhà thờ, hay cột cờ có độ tương đồng hình ảnh khá giống nhau, thậm chí nếu chụp ở 1 góc nào đó thì kể cả con người cũng khó phân biệt được. Nên data như vậy rất phù hợp với kỹ thuật fine-grained classification.
Fun stuff
- Với query là ảnh con cá này:

Model predict ra cơ sở nước mắm Phú Quốc.
model của team mình predict ra label 70 - Cơ sở chế biến nước mắm Phú Quốc. Mặc dù sau khi kiểm tra 497 hình của class 70 này bằng mắt, không hình nào trong training data có hình con cá. Mình gọi đây là: The next level of AI.
- Hình tượng chúa ở Brazil được cho làm query, trong khi đây là cuộc thi Landmark ở Việt Nam, hình này còn xuất hiện vài lần trong tập test.

- Mình rất muốn đi DisneyLand ở Việt Nam 😦

- Rất nhiều hình trong training data sử dụng ảnh của các site khác, mình tò mò là bên Zalo đã xin phép bản quyền chưa.
P.s: I love Vietnam

Mình không biết 3 hình này thuộc địa danh nào ở Việt Nam, nhưng rất đẹp.
Xin chân thành cảm ơn sự giúp đỡ và hỗ trợ của VietAI trong quá trình mình tham gia cuộc thi. Dù không được vào Top 3 nhưng cũng là 1 trải nghiệm thú vị với nhiều điều đáng học hỏi.
References
- Chum, Ondřej, James Philbin, Josef Sivic, Michael Isard, and Andrew Zisserman. 2007. “Total Recall: Automatic Query Expansion with a Generative Feature Model for Object Retrieval.” In IEEE International Conference on Computer Vision (ICCV).
- Iscen, Ahmet, Giorgos Tolias, Yannis Avrithis, Teddy Furon, and Ondřej Chum. 2017. “Efficient Diffusion on Region Manifolds: Recovering Small Objects with Compact CNN Representations.” In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Noh, Hyeonwoo, Andre Araujo, Jack Sim, Tobias Weyand, and Bohyung Han. 2017. “Large-Scale Image Retrieval with Attentive Deep Local Features.” In IEEE International Conference on Computer Vision (ICCV).
- Radenović, Filip, Giorgos Tolias, and Ondřej Chum. 2019. “Fine-Tuning CNN Image Retrieval with No Human Annotation.” IEEE Transactions on Pattern Analysis and Machine Intelligence.
- Smith, Leslie N. 2017. “Cyclical Learning Rates for Training Neural Networks.” In IEEE Winter Conference on Applications of Computer Vision (WACV).