Working with AI Coding Agents
I’ve been spending a lot of time with AI coding agents lately, and I have thoughts.
My weapon of choice is OpenCode, a terminal-based interface that lets me talk to Claude Opus 4.5 without leaving the comfort of my terminal. I’m fond of TUI apps in general; they’re fast, responsive, vim-friendly, and refreshingly free from the visual clutter that plagues modern GUI applications. There’s something satisfying about a tool that does exactly what you ask, renders in milliseconds, and doesn’t need 2GB of RAM to display a text input field.[1]
Over months of daily use, my workflow has crystallized into a rhythm: Plan, then Build, then Interrupt the moment it goes off the rails. The last part is crucial. AI agents have a tendency to keep building confidently in the wrong direction, and if you let them run unsupervised, you’ll come back to a codebase that vaguely resembles what you asked for but solves an entirely different problem. So I commit frequently, undo liberally, and take incremental steps. And I review everything at least twice, because these models produce subtle bugs that slip past a casual glance, the kind that work fine in the happy path but explode the moment real data touches them.
This post is a field report: what works, what breaks, and the mental model that has helped me extract actual value from these tools without losing my sanity.
Where AI Agents Shine
I want to start with the wins, because there are genuine wins here.
For all the frustrations I’ll get into later, AI agents have fundamentally changed how I approach certain categories of work. The tasks that used to feel like a tax on my time, the ones I’d procrastinate on for days because they were tedious rather than hard, now get delegated without a second thought. And the agents handle them reasonably well.
Configuration management is perhaps the clearest example. Need to install a handful of Neovim plugins, reorganize your keymaps to something more sensible, or clean up config files that have accumulated cruft over the years? Hand it over. The agent will navigate the documentation, suggest sensible defaults, and handle all the YAML/JSON/Lua shuffling that nobody actually enjoys doing. I used to spend entire evenings getting my dotfiles just right; now I describe what I want and review what comes back.
Boilerplate and scaffolding is another sweet spot. When I need to spin up a proof-of-concept or get the skeleton of a new feature in place, AI agents work remarkably fast. They’re not going to produce production-quality code on the first pass, but that’s not the point. The point is to get something running that I can iterate on, and for that purpose, they deliver.
Proofreading has been surprisingly valuable. I’m not a native English speaker, and I want to write faster without sacrificing clarity. The agent catches typos, suggests better wording, and generally speeds up my writing process. It’s not perfect; left to its own devices, it produces documentation so verbose it feels like an insult to the reader’s intelligence. But with the right prompting and aggressive editing, it’s a genuine productivity boost.
And for what I’d call low-hanging refactors, renaming variables across a codebase, extracting small functions, moving code between files, AI agents are remarkably reliable. These mechanical transformations are tedious for humans but trivial for machines, exactly the kind of work we should be offloading.
As a general-purpose assistant for managing notes, converting between formats, fixing grammar, the current models rarely disappoint. This might actually be their highest and best use: not as a replacement for thinking, but as a tireless helper for the tasks that don’t require much thinking in the first place.
Even code review tools like GitHub Copilot, despite their high false-positive rate and general noise, occasionally catch issues I would have missed. It’s not reliable enough to replace careful review, but as a supplementary set of eyes, it has earned its keep.
Where AI Agents Break Down
Now for the frustrations, and there are plenty.
The problems tend to emerge the moment you step outside the well-trodden paths. Configuration management works great until the configuration becomes complicated. I wanted to turn off line breaks, and only line breaks, in dfmt.[2] Simple enough request, right? I pointed Opus 4.5 at the documentation, explained exactly what I needed, and watched it hallucinate configuration options that don’t exist. It wasn’t even close. The model confidently produced settings that looked plausible but had no basis in reality, and it kept doing so no matter how many times I redirected it to the actual docs.
This pattern repeats across domains. The agent is great until it isn’t, and the transition happens without warning.
Sometimes the failures are subtle. Other times they are catastrophic. I asked Claude to fix a Docker permission issue, a straightforward problem with several reasonable solutions. It chose to run rm -rf data/ on a folder containing terabytes of indexed vectors. When I asked why, it tried to convince me nothing was lost because the folder was in .gitignore. “Gitignored equals unimportant,” apparently. Only after I pushed back did it acknowledge that yes, it had just deleted the most important folder in the codebase with no way to recover it. AI agents will take the shortest path to “success,” even if that path involves deleting your data. And when they make mistakes, they’ll construct narratives to minimize them.
Even straightforward codebases aren’t safe. I tested an agent on a standard Golang backend with conventional project structure. It decided to remove internal dependencies entirely.
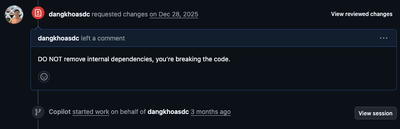
The dependencies were clearly in use. The build broke immediately. Yet the agent needed explicit correction to stop.
Bug fixing is a particular weakness. I ran into an Arrow error involving nested structs in Parquet files: ArrowNotImplementedError: Cannot write struct type 'force_update' with no child field to Parquet. The actual issue was a nested struct inside a field, but the agent kept insisting the problem was NaN values preventing type inference. It wasn’t. I spent hours going back and forth, with the model confidently explaining a problem that didn’t exist while ignoring the problem that did. Eventually I fixed it myself, the old-fashioned way.
Working with growing codebases reveals another limitation. When I set up a new training pipeline, the initial code generation was fine. But as the codebase grew, Opus 4.5 started to deteriorate. Simple function calls got hallucinated. Operations as basic as renaming a function required multiple API calls to fix, because the model kept introducing new errors while fixing old ones. It’s like watching someone dig themselves into a hole, except you’re paying per token for the shovel.
The data science workflow exposed an assumption problem that I find genuinely concerning. I gave the agent a multilabel classification dataset. Without asking about the nature of the data, it assumed single-label classification and proceeded to implement the wrong model entirely. What happens when the human doesn’t know enough to catch that mistake? The model ships, the metrics look reasonable, and nobody realizes the fundamental approach was wrong from the start.
There’s also a code quality issue that’s hard to pin down but impossible to ignore. The models seem to have learned heavily from Kaggle notebooks, so when you ask for a training pipeline, you get unstructured, messy code that feels like it was written for a weekend competition rather than a production system. Duplicate logic everywhere. I constantly have to force it to use existing methods instead of reimplementing the same functionality three different ways.
And perhaps most insidiously: these tools make you lazier. I’ve started delegating all the boring data manipulation tasks to agents, which is fine until I realize I don’t understand my own codebase anymore. Sometimes I force myself to do refactors manually, not because the agent can’t handle them, but because I need to maintain a mental model of what’s actually happening. The moment you lose that, you’re debugging code you don’t understand with tools that confidently explain things that aren’t true.
Journey 1: Animating the Tower of Hanoi
I wanted to create an educational video about the beauty of algorithms and data structures. Inspired by Concrete Mathematics (Graham et al. 1989) and Inquiry-Based Enumerative Combinatorics (Petersen 2019), and paying homage to my capital city, I decided to animate the Tower of Hanoi. This isn’t exactly unexplored territory; 3Blue1Brown has a famous video on the topic:
But I wanted to introduce something most people aren’t aware of: Hanoi Graphs, the elegant structure that emerges when you encode every possible state of the puzzle as vertices in a graph. The result is a Sierpinski triangle, and it’s beautiful. I wanted to show that.
So I gave Claude Opus 4.5 two tasks:
- Use manim to visualize the Tower of Hanoi with N=4 disks.
- Encode the state space of the problem and visualize it as a Sierpinski graph.
The first task started promisingly and then failed in a way that was almost comedic. The initial render had the disks upside down:
After a few rounds of tweaking, it produced something usable. But here’s the thing: it looked exactly like every other Tower of Hanoi animation on YouTube. Which shouldn’t be surprising, given that manim is the dominant framework for math videos and everyone uses the same visual language. The result was correct but unremarkable:
The second task was a disaster. I wanted the Hanoi Graph, the Sierpinski structure that makes this problem genuinely interesting. What I got was a mess, and no amount of prompting could fix it:
I tried everything. I explained the mathematical structure. I provided references. I broke the problem into smaller pieces. The model kept producing graphs that were structurally wrong in ways that suggested it had no understanding of what it was trying to build. It wasn’t making small errors; it was failing to grasp the fundamental relationship between the puzzle states and their graph representation.
This is the pattern I keep running into: AI agents can reproduce what they’ve seen before, but they struggle to construct something that requires genuine understanding of the underlying structure. A Tower of Hanoi animation exists in countless tutorials and YouTube videos; the training data is rich with examples. A Hanoi Graph visualization is rarer, more mathematical, and apparently beyond what the model can synthesize from first principles.
Journey 2: Leetcode Partner
I don’t have access to the performance metrics that research labs publish about their models’ coding abilities. What I have is my own experience, and my experience says this: AI agents are surprisingly bad at algorithmic puzzles.
This caught me off guard. These are the kinds of problems that feel like they should be in the model’s wheelhouse: well-defined inputs and outputs, thousands of examples in the training data, clear success criteria. Leetcode solutions are all over the internet. How hard could it be?
Hard enough, apparently. I’ve documented several failures in a separate post, and the pattern is troubling. Opus 4.5 produced a Sideway Tower of Hanoi solution that output the correct move count (26 for n=3) while violating the fundamental constraint that larger disks cannot sit on smaller ones. The bug was invisible unless you traced through the actual peg states. GPT 5.2 went the other direction: it confidently declared my correct solution incorrect, complete with an elaborate but flawed analysis of why the code would “recurse forever.” It even claimed my algorithm would produce 24 moves instead of 26, implying it found something better than the mathematical optimum. Let that sink in.
What makes this frustrating is the confidence. Neither model hedged. Neither said “I’m not sure about this” or “you might want to verify.” They presented wrong answers with the same authoritative tone they use for everything else, which means you can’t calibrate your trust based on how the answer sounds. You have to verify everything yourself, which defeats half the purpose of having an assistant in the first place.
Verdict
So does working with AI agents actually improve productivity? For software engineers, ML engineers, anyone who writes code for a living?
Yes. With caveats.
If you want a quick proof-of-concept, some experimental models to test a hypothesis, and you give absolutely no damn about code quality, AI agents work wonders. They’ll get you to “something running” faster than you could get there yourself, and sometimes that’s exactly what you need. Not every piece of code deserves careful architecture. Not every script needs to be maintainable. For throwaway work, these tools are a genuine force multiplier.
For low-hanging refactors, generating documentation, moving code around, renaming things across a codebase, AI agents are reliable enough that I don’t think twice before delegating. The tedious mechanical work that used to eat up afternoons now takes minutes. That’s real value.
But for anything that requires genuine understanding of a codebase, anything that involves large-scale redesign or careful reasoning about edge cases, the experience is closer to supervising a new intern than collaborating with a senior engineer. The intern is enthusiastic and fast. The intern will confidently propose solutions that completely miss the point of your existing architecture. The intern will introduce subtle bugs while fixing obvious ones. And the intern will never tell you when they’re out of their depth, because they don’t know they’re out of their depth.
The mental model that works for me: AI agents are tools for amplifying your own understanding, not replacing it. They’re most valuable when you already know what good looks like and can recognize when the output falls short. They’re most dangerous when you’re learning something new and can’t distinguish confident nonsense from correct explanations.
This clip from ThePrimeTimeagen captures the experience perfectly:
https://www.youtube.com/shorts/kYb1TEYZXjg
Use them. They’re useful. Just don’t trust them.
OpenCode still has some annoying input issues, but nothing deal-breaking. ↩︎
A D language formatter. ↩︎
References
- Graham, Ronald L., Donald E. Knuth, and Oren Patashnik. 1989. Concrete Mathematics: A Foundation for Computer Science. Addison-Wesley.
- Petersen, T. Kyle. 2019. Inquiry-Based Enumerative Combinatorics. Springer.